为什么使用多线程
减少延迟,提高吞吐量。
延迟指从发出请求到收到响应过程的时间,吞吐量指单位时间内能完成的请求个数。
多线程应用场景
想要降低延迟提高吞吐量主要有两个维度的方法,第一个是优化算法,第二个是最大化硬件的利用率。前者属于算法范畴,后者就和并发编程息息相关了。而对于计算机硬件来说最主要的就是两个硬件,一个是IO一个是CPU。在操作系统层面,操作系统已经为我们对硬件的利用率做了很大的优化,但是还是不够,在CPU与IO配合使用的利用率更加需要我们程序员去优化。也就是说,我们需要去解决CPU和IO设备综合利用率的问题
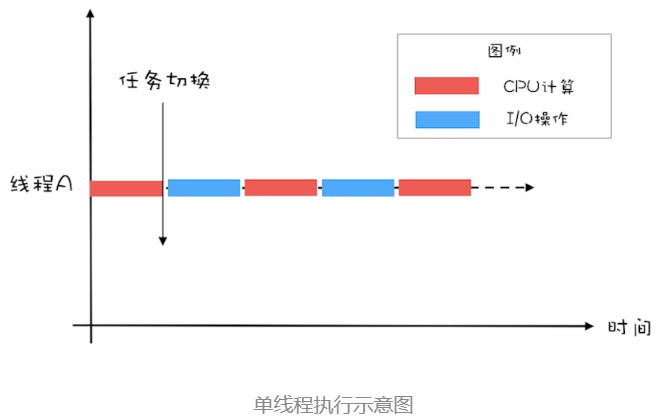
例如在单线程中,假设CPU和IO的执行时间相同,那么这个时候CPU和IO设备的利用率都是50%。
但在双线程中,CPU和IO设备执行时间都是一样的,这个时候,CPU在等待IO的时候又可以去执行下一个线程的,这个时候CPU和IO的利用率就是100%。
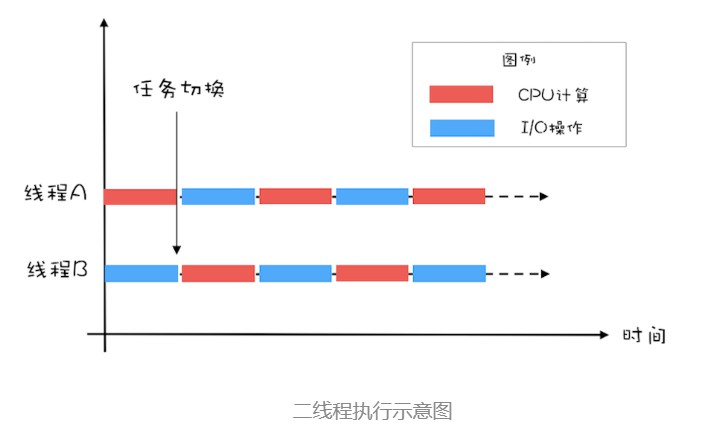
所以,如果 CPU 和 I/O 设备的利用率都很低,那么可以尝试通过增加线程来提高吞吐量。
在单核时代,多线程主要就是用来平衡 CPU 和 I/O 设备的。如果程序只有 CPU 计算,而没有 I/O 操作的话,多线程不但不会提升性能,还会使性能变得更差,原因是增加了线程切换的成本。但是在多核时代,这种纯计算型的程序也可以利用多线程来提升性能。为什么呢?因为利用多核可以降低响应时间。
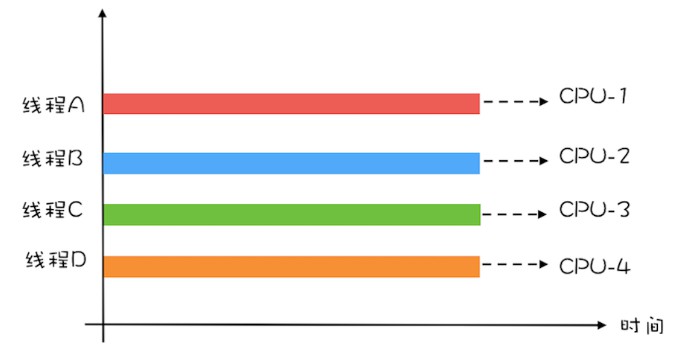
例如计算 1+2+… … +100 亿的值,如果在 4 核的 CPU 上利用 4 个线程执行,线程 A 计算 [1,25 亿),线程 B 计算 [25 亿,50 亿),线程 C 计算 [50,75 亿),线程 D 计算 [75 亿,100 亿],之后汇总,那么理论上应该比一个线程计算 [1,100 亿] 快将近 4 倍,响应时间能够降到 25%。一个线程,对于 4 核的 CPU,CPU 的利用率只有 25%,而 4 个线程,则能够将 CPU 的利用率提高到 100%。
创建多少线程合适
创建多少线程合适需要考虑应用场景,通常情况下我们的程序都是由IO操作和CPU操作一起执行的,而IO操作相对于CPU操作来说是非常耗时的。所以大部分情况下,I/O 操作执行的时间相对于 CPU 计算来说都非常长,这种场景我们一般都称为 I/O 密集型计算。
和 I/O 密集型计算相对的就是 CPU 密集型计算了,CPU 密集型计算大部分场景下都是纯 CPU 计算。I/O 密集型程序和 CPU 密集型程序,计算最佳线程数的方法是不同的。
对于 CPU 密集型计算,多线程本质上是提升多核 CPU 的利用率,所以对于一个 4 核的 CPU,每个核一个线程,理论上创建 4 个线程就可以了,再多创建线程也只是增加线程切换的成本。所以,对于 CPU 密集型的计算场景,理论上线程的数量 =CPU 核数就是最合适的。不过在工程上,线程的数量一般会设置为CPU 核数 +1,这样的话,当线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以顶上,从而保证 CPU 的利用率。
对于 I/O 密集型的计算场景,比如前面我们的例子中,如果 CPU 计算和 I/O 操作的耗时是 1:1,那么 2 个线程是最合适的。如果 CPU 计算和 I/O 操作的耗时是 1:2,那多少个线程合适呢?是 3 个线程,如下图所示:CPU 在 A、B、C 三个线程之间切换,对于线程 A,当 CPU 从 B、C 切换回来时,线程 A 正好执行完 I/O 操作。这样 CPU 和 I/O 设备的利用率都达到了 100%。
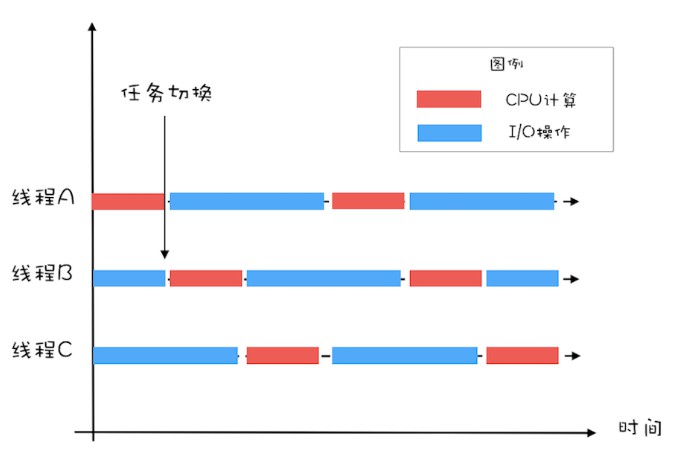
最佳线程数 =1 +(I/O 耗时 / CPU 耗时)
对于多核来说只需要乘上核数就行:最佳线程数 =CPU 核数 * [ 1 +(I/O 耗时 / CPU 耗时)]