什么是Trie
Trie是字典树,前缀树。Trie的思想就是使用空间换时间,它是一种专门致力于字符串查询的树,因为它的子节点是所有包含的字符,所以它是一个多叉树(使用空间大),当我们对一个字符串进行查询的时候它的时间复杂度是O(字符串长度),所以当个字符串集合非常大的时候是不影响Trie的性能的。
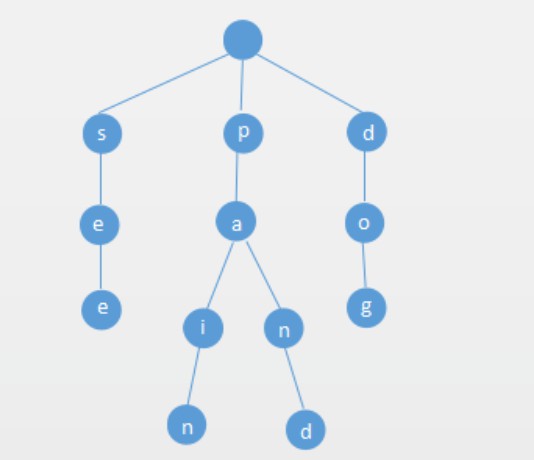
这是Trie的基本结构,里面存放了see,dog,pain,pand
在Trie中添加单词
因为Trie是专门对字符串进行操作的,这里我们选择对Trie中添加一个单词。
主要思路就是:我们对需要添加的单词进行for循环取出每个字符,然后我们同时在树中进行遍历,比如我们取出第一个字符是a,那我们就在根节点的next(这里是一个map存放着所有的子节点)中查找是否有a这样的节点,如果没有我们就创建,如果有我们进入这个结点继续后面的操作,比如下一个字符是p。。。
java代码
1 | public class Trie { |
在Trie中查找单词
基本思路:
对于查找其实就是遍历这个单词字符串然后在Trie中进行遍历,如果符合则继续遍历,不符合就直接return false。如果遍历到最后,我们就查看最后那个节点的单词标志是不是true如果是那么就return true。
java代码:
1 | public boolean contains (String word) { |
在Trie中进行前缀查询
基本思路:
对于前缀查询其实跟查找差不多,只是我们不需要判断最后一个节点是不是单词了,因为这里只是判断前缀。
java代码
1 | public boolean prefix (String word) { |
在Trie进行模式匹配
其实是一个LeetCode题目

解题思路:
主要就是要解决这个.的匹配问题,这里我们使用递归。当我们搜索一个字符串是否存在的时候(包括.的字符串),我们首先定义一个递归函数,参数为当前查找的node,字符串,当前字符的索引,返回是boolean。
我们递归函数的最根本条件就是当index等于这个查询的字符串的长度的时候我们就返回当前节点是否是单词的标志。
但我们进行查找的时候我们现在root的node中执行该函数,然后我们字符索引是0,获取到第一个字符,我们首先要判断这个字符是不是等于.,如果不等于,我们判断当前节点的next中是否有当前字符的node如果没有直接返回false,如果有那继续递归到当前节点的next.get(当前字符)的节点,索引是index + 1。
如果是. 那么我们就对这个node.next的key进行遍历,并且在遍历中调用递归函数,写法跟上面差不多
具体代码实现
1 | public class WordDictionary { |
LeetCode中的键值映射题目

解题思路:
其实前面查找都差不多,主要就是我们对这个进行前缀查找之后到了最后那个节点的时候我们需要对后面所有单词的value进行相加最终返回。
我们这里可以使用递归,比如我们已经进行前缀查询并且到了前缀查找字符的最后一个字符,我们书写一个sum递归函数,目的是计算符合这个前缀的单词的value的总和,其实就是获取都前缀最后节点的字数所形成的所有单词的value和。
这个递归函数的参数只有一个Node,这个node就是前缀遍历到最后的节点。然后我们的根本条件就是node的next的size为0的时候也就是最后没有字符(结尾)的时候直接返回该结点的value,然后我们定义一个result,每次result都对当前节点的value进行+=操作,然后我们对next的key进行遍历,在遍历中进行递归调用,递归到node为当前node.next.get(遍历到的key)
具体代码:
1 | public class MapSum { |