什么是优先队列
普通队列是先进先出的数据结构,而对于优先队列则是以优先级为准则的,优先级越大的先出队。就比如医院挂急诊的优先级大于普通排队就诊的,比如在游戏中自动打怪设置,当地图中出现级别高的野怪先打级别高的等等。
如果我们实现优先队列使用普通的线性结构,那么当我们入队的时候时间复杂度就是O(1),但出队的时候我们的时间复杂度就是O(n),因为出队的时候是优先级最高的出队,所以我们需要遍历整个队列寻找优先级最高的元素。
如果我们实现优先队列使用的顺序线性结构,那么我们出队的时间复杂度就是O(1),因为原本队列就是依靠优先级排列的,这时候我们出队只需要取出第一个元素就行了。但是,当我们进行入队操作的时候我们就需要维持队列的顺序性,这时候入队就是O(n)的时间复杂度了。
相较于前面两种实现方法,使用堆来实现优先队列的入队操作和出队操作都是O(logn)的时间复杂度,这是非常快的。

什么是堆
堆其实就是按照层由上到下,由左到右的树结构,其中可以分为最大堆和最小堆(根元素为最大的元素就是最大堆)
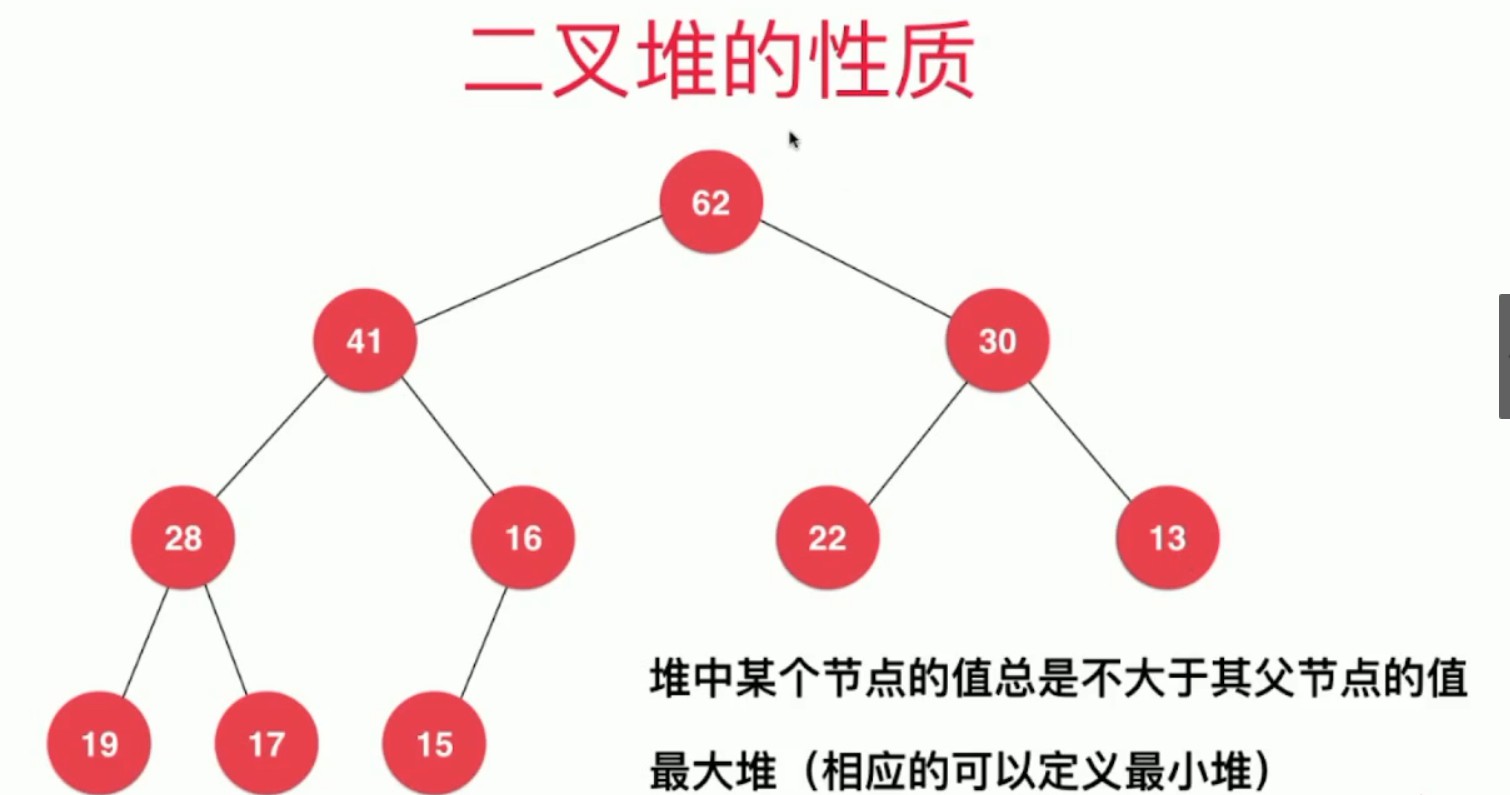
当我们使用数组实现堆的时候,这时候父子节点的索引值存在着一种数学关系。
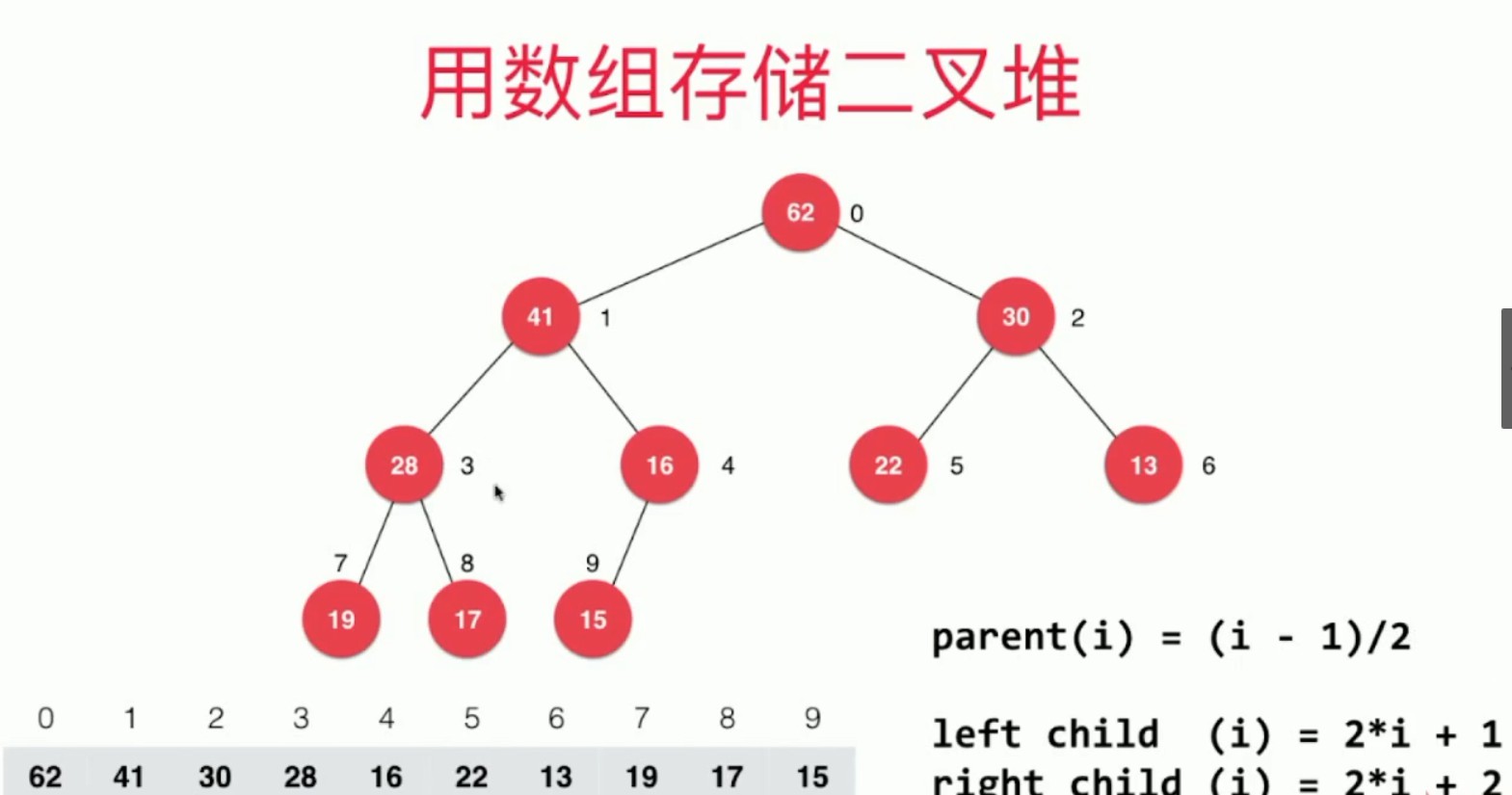
当索引从0开始的时候,父亲节点的索引就是子节点的索引-1再除以2(取整的性质,所以左右孩子都一样),相应的,左孩子就是父亲节点索引乘2+1,右孩子则是左孩子+1。
通过这个关系我们就可以很轻松的使用数组存储二叉堆。
最大堆的代码实现
1 | /** |
最大堆的入队和出队的操作
在上述代码中,其他操作都是最基本的,但是对于插入和移除元素就会稍微复杂了。
当我们插入元素的时候,我们需要在数组最后插入元素,但是插入元素的大小不一定性决定着我们需要重新排列这个二叉堆使它还满足最大堆的特性。所以我们只需要和插入元素的父亲节点比较,如果我们插入的节点大于父亲节点了则交换,然后再和交换后的父亲节点比较,一直到根节点或者子节点小于父亲节点了。
当我们移除元素的时候,其实就是移除堆中的顶层元素,这时候如果直接移除的话,那么堆就会变成两个堆,这样整合成一个堆的话太复杂,这时候我们可以将堆底元素和堆顶元素交换,然后再删除堆底元素(原来堆顶元素),然后我们通过现在堆顶元素和它的左右孩子最大的作比较,如果小于最大的那么就交换,然后再次和左右孩子做比较直到自己没有左右孩子为止。
使用堆来实现优先队列
1 | /** |
关于LeetCode中优先队列的问题

分析: 我们需要获取频率出现最高的元素,我们需要将频率和元素(key)存入一个map中,然后遍历这个数组,当map不存在相应key的数组中的元素,则将value设置为1,如果存在value++。
然后我们遍历这个map中的key,将key存入优先队列中(容量为k),当k的容量存满了并且还需要添加元素到优先队列的时候就判断优先队列优先度最高的元素和插入元素的优先度,如果插入元素的优先度高于现在队列中最高的,那么就将元素插入到队列中,知道整个map遍历完。
代码实现:
1 | class Solution { |