什么是集合(Set)
简单来说,集合就是一个不能存放重复元素的数据结构,通常可以运用于客户统计(网站访问人数),词汇量统计等等。
定义Set接口
1 | public interface Set<E> { |
使用二分搜索树实现集合
对于二分搜索树有一个很重要的特性就是它是根据元素的大小来放入元素到树中的,所以二分搜索树基本是不存在相同元素的,我们就可以通过二分搜索树底层实现集合
这是上一篇博客写的二分搜索树的相关代码:
1 | /** |
这时候我们就可以使用二分搜索树来实现集合了,很简单,直接封装一个二分搜索树然后调用方法就行了。
1 | /** |
使用链表来实现集合
链表中有一个contains方法,我们可以在调用add方法的时候使用contains方法判断原来集合中是否已经存在该元素了,如果已经存在那么就添加失败。其他的也是直接调用方法。
1 | /** |
二分搜索树和链表实现集合的比较
在上面实现链表集合的时候我们很容易就会发现,链表集合的增加操作的时候需要先判断整个链表中是否存在该元素,那么这样就需要O(n)的时间复杂度了,在删除,查找元素的时候都是和普通链表一样O(n)的时间复杂度。可以说链表实现的集合的效率并不是很高。
那么我们再来看一看二分搜索树实现的集合的时间复杂度。当我们添加元素的时候我们是依靠二分搜索树的特性来添加的
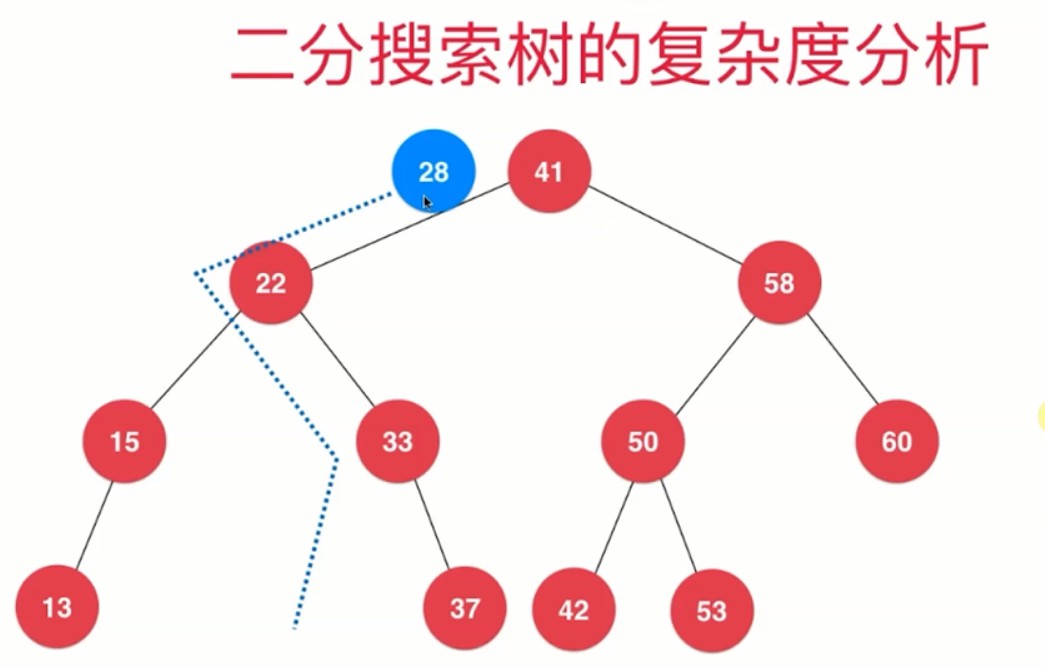
比如我们需要添加一个元素的时候,我们就需要先判断大小,然后根据树的特性一层一层遍历,这个时候我们就会发现,我们的时间复杂度是和这个二分搜索树的高度呈线性关系的。
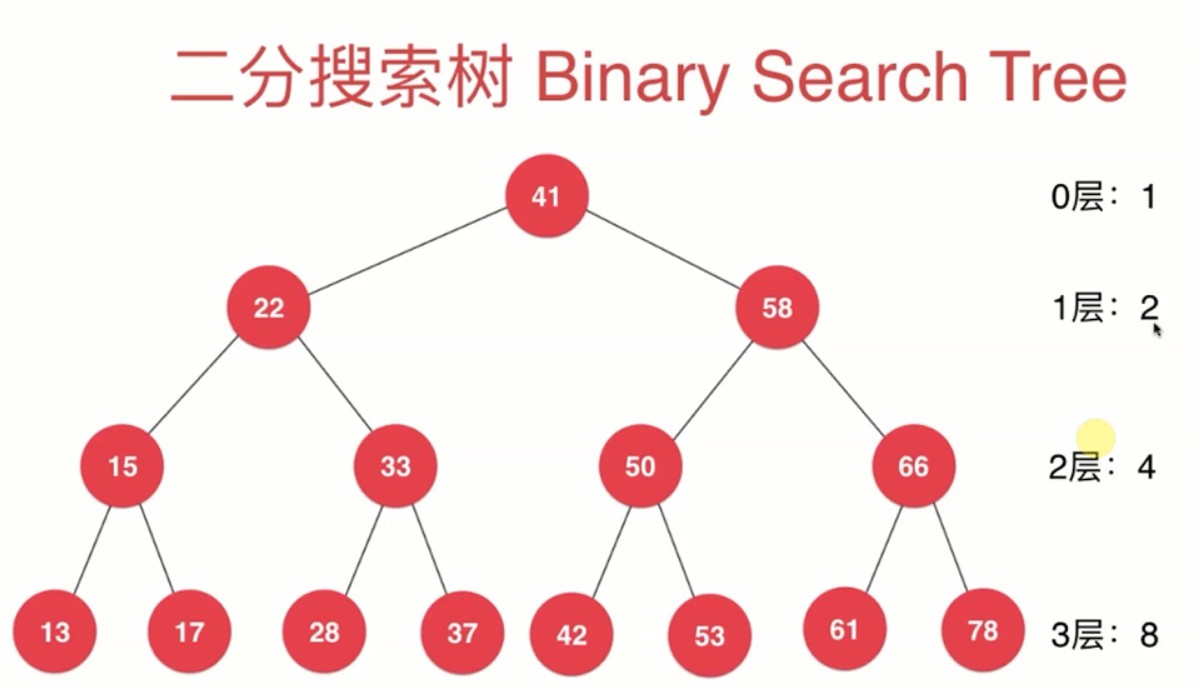

然后我们通过运算就可以得出一个平衡二叉树h层一共有2的h次方-1个元素,我们就很容易得出时间复杂度为log2(n+1),忽略常数,那么就是logn。
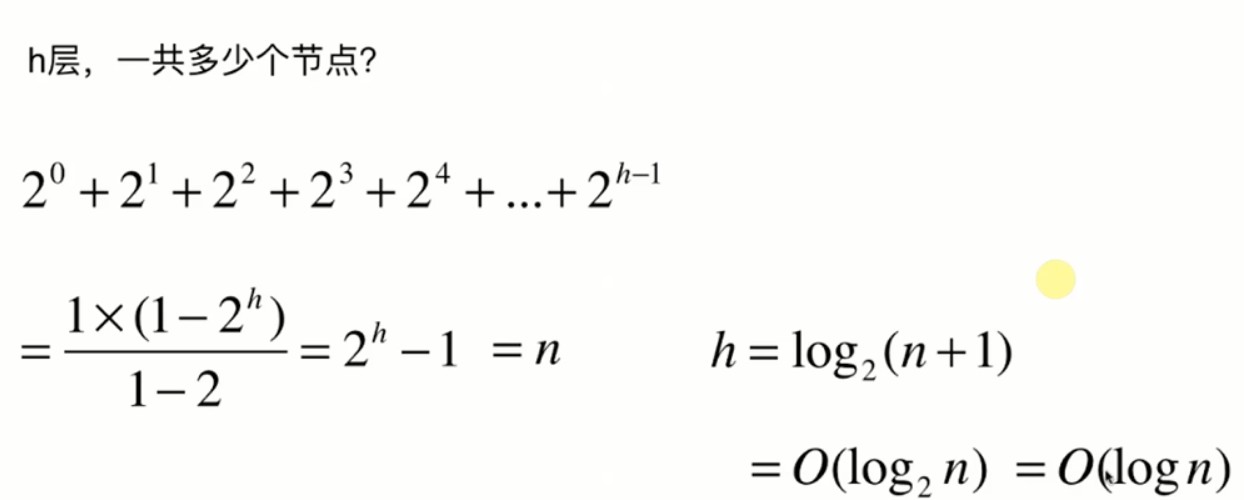
而logn和n的差距在基数很大的时候差距特别明显

所以说二分搜索树实现的集合会比链表实现的集合快很多。当然这也是考虑树的最好情况。当树不为平衡二叉树的时候,最坏情况也会是O(n)。
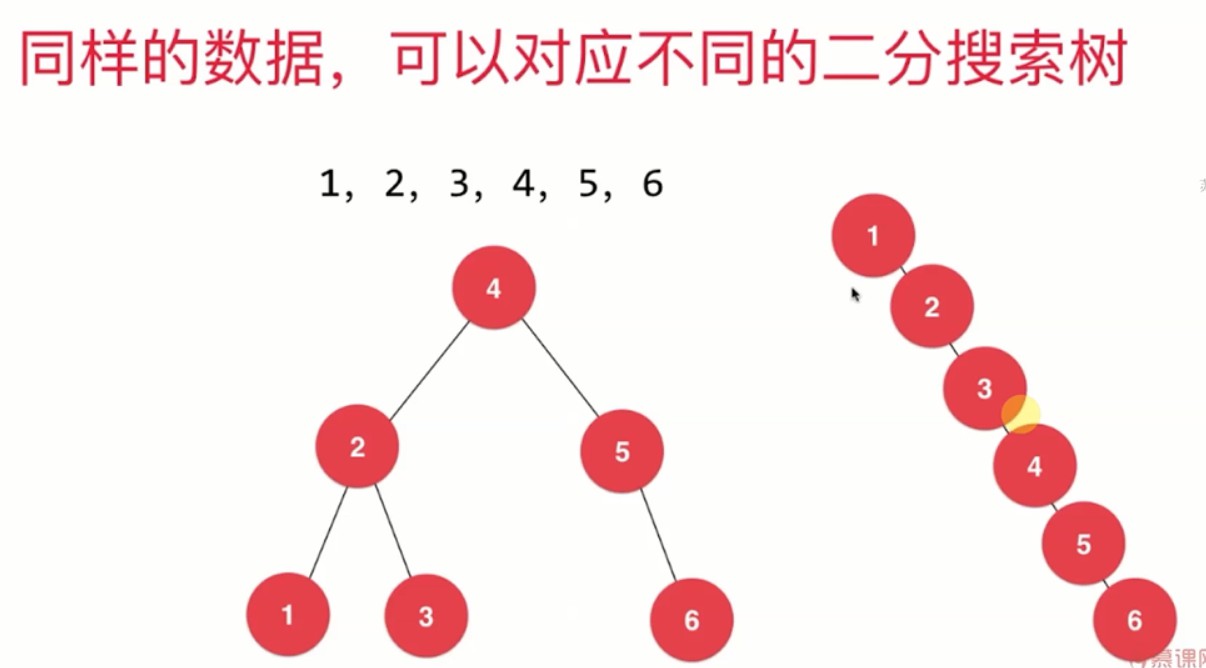
如上图右边,我们看到当树成一边排列的时候,它的时间复杂度就是O(n)。
LeetCode上解决关于集合的题目
题目是这样的:

对于这道题,我们可以遍历这个words数组,然后得到其中的某个元素再次遍历字符串的每个字母,然后通过原先定义的摩尔斯密码表数组和字符相对应,之后我们就可以获取到这个单词的摩尔斯密码,我们循环完一次之后,我们就把得到的摩尔斯密码拼接成字符串然后存入到set中,最终循环完成之后我们只要返回set的size就行了。
实现代码:
1 | /** |
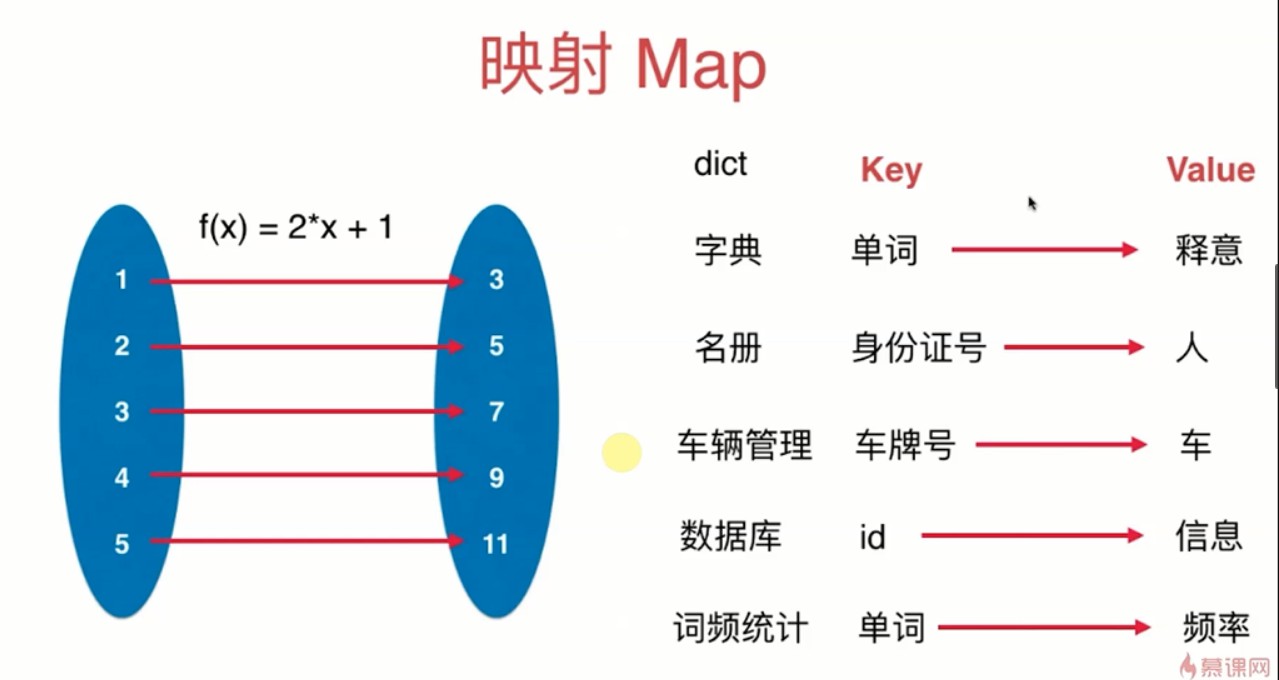
什么是映射(Map,字典)
映射,在定义域中每一个值在值域都有一个值与他对应
存储(键,值)数据对的数据结构(Key,Value)
根据键(Key),寻找值(Value)
定义Map接口
1 | /** |
链表实现Map
使用链表实现Map其实只需要将私有类Node里面的字段e更改为key和value就行。当然BinarySearchTree也是如此
实现代码:
1 | /** |
二分搜索树实现映射(Map)
对于BinarySearchTree来说实现Map也是利用它原先的方法
代码实现:
1 | /** |
链表Map和二分搜索树Map比较
测试代码:
1 | public class TestMap { |
两者时间差异:
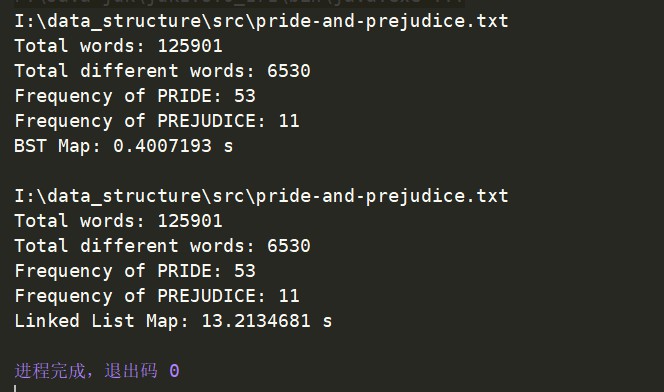
可以看出,二分搜索树实现的Map的时间性能是远高于链表实现的Map的。
因为对于链表实现修改某一映射对应的value值的时间复杂度是O(n),我们需要一个一个去遍历知道找到key符合的元素。
而对于二分搜索树实现的Map来说,它修改一个value的时间复杂度是跟二叉树的高度相关的,也就是说它的时间复杂度是O(logn)级别的,所以当数据量大的时候,二分搜索树的优势非常明显。当然我们还需要考虑最坏的情况,那就是这个二分搜索树变成了类似于链表的树,那这时候时间复杂度就是O(n)了。
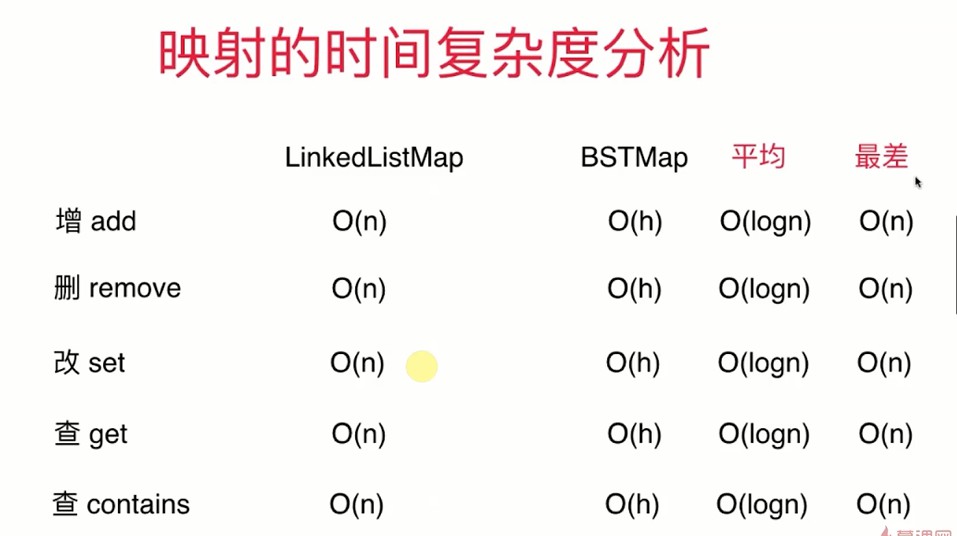
但是有个细节需要注意的是,链表实现的Map的key是无序的,上文中的set也是无序的。但是二分搜索树实现的set和map都是有序的(这也是它这么快的一部分原因)。
使用Map来实现Set
我们可以发现,其实Set就是一个没有value的的Map。所以,当我们底层实现了一个映射,集合我们就可以理解成Map<K, V>中value为null的情况,对于不管是k,它所对应的的value都为null。
所以当我们在Map中只考虑K的时候,整个Map数据结构就变成了K的集合。